- Formalism
- Hierarchies and Data Cubes
- Pan and Zoom
- Implementation and Release
- People
- Publications and Presentations
|
The Polaris project at Stanford University is no longer active. However,
commercial products are now available by
www.tableausoftware.com |
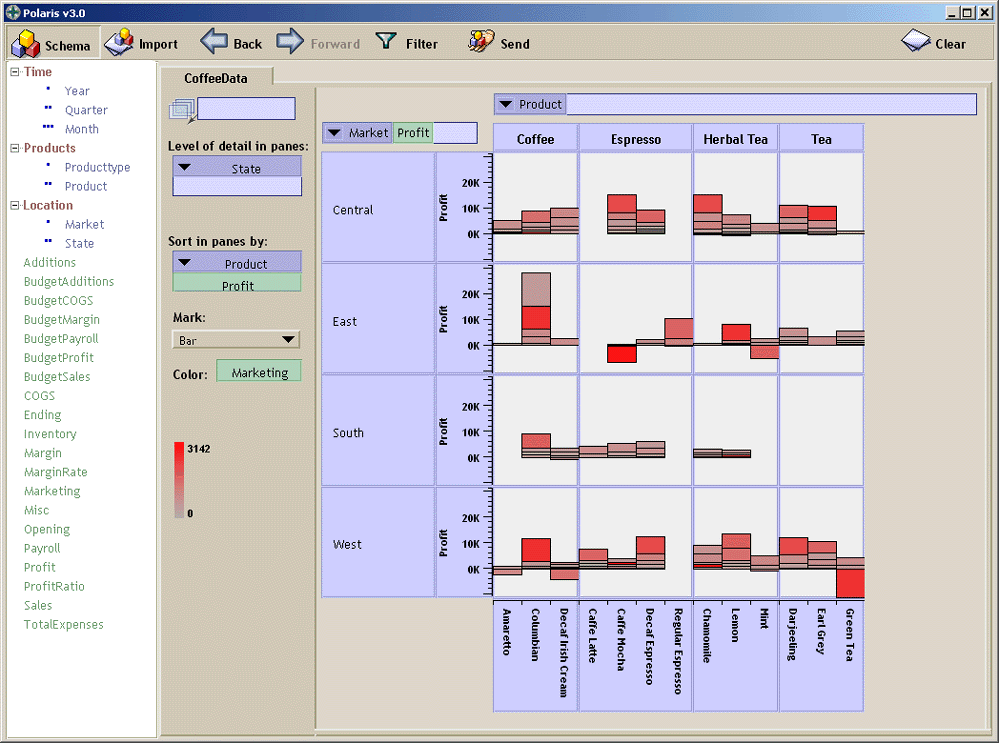
In the last several years, large multi-dimensional databases have become common in a variety of applications such as data warehousing and scientific computing. Analysis and exploration tasks place significant demands on the interfaces to these databases. Because of the size of the data sets, dense graphical representations are more effective for exploration than spreadsheets and charts. Furthermore, because of the exploratory nature of the analysis, it must be possible for the analysts to change visualizations rapidly as they pursue a cycle involving first hypothesis and then experimentation.
|
Formalism
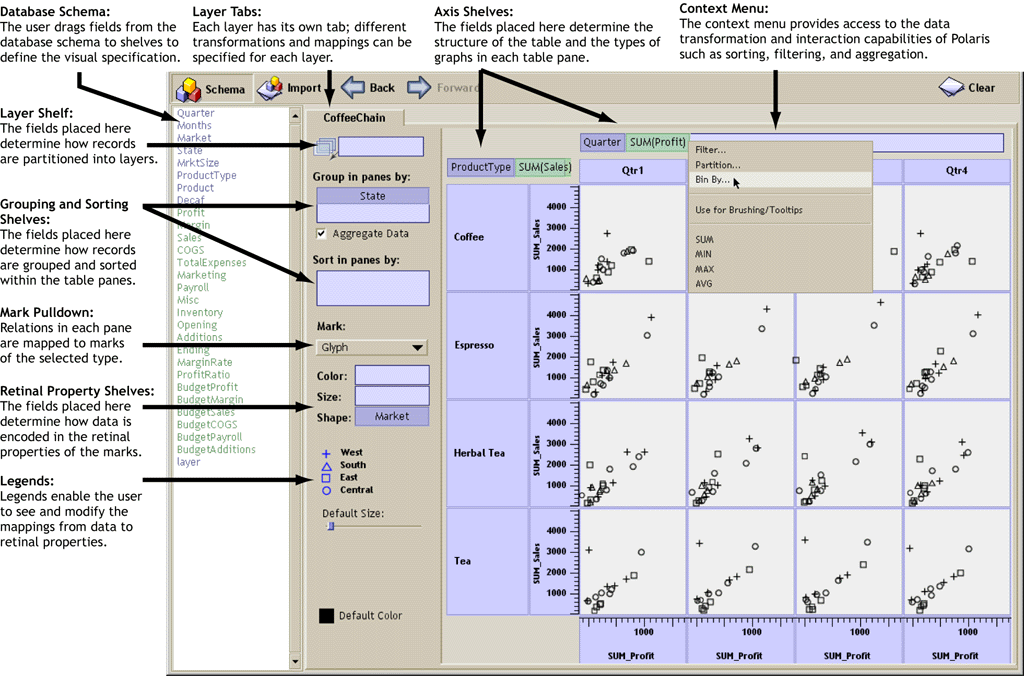
The Polaris interface is simple and expressive because it is built on top of a formalism for describing table-based graphical representations of relational databases. Specifications in this language are compiled by our interpreter into a set of efficient queries and drawing operations to generate displays. The formalism precisely defines:
|
- The mapping of data sources to layers. Multiple data sources may be combined in a single Polaris visualization. Each data source maps to a separate layer or set of layers.
- The number of rows, columns, and layers in the table and their relative orders (left to right as well as back to front). The database dimensions assigned to rows are specified by the fields on the x shelf, columns by fields on the y shelf, and layers by fields on the layer (z) shelf. Multiple fields may be dragged onto each shelf to show categorical relationships.
- The selection of records from the database and the partitioning of records into different layers and panes.
- The grouping of data within a pane and the computation of statistical properties and aggregates. Records may also be sorted into a given drawing order.
- The type of graphic displayed in each pane of the table. Each graphic consists of a set of marks, one mark per record in that pane.
- The mapping of data fields to retinal properties of the marks in the graphics. The mappings used for any given visualization are shown in a set of automatically generated legends.
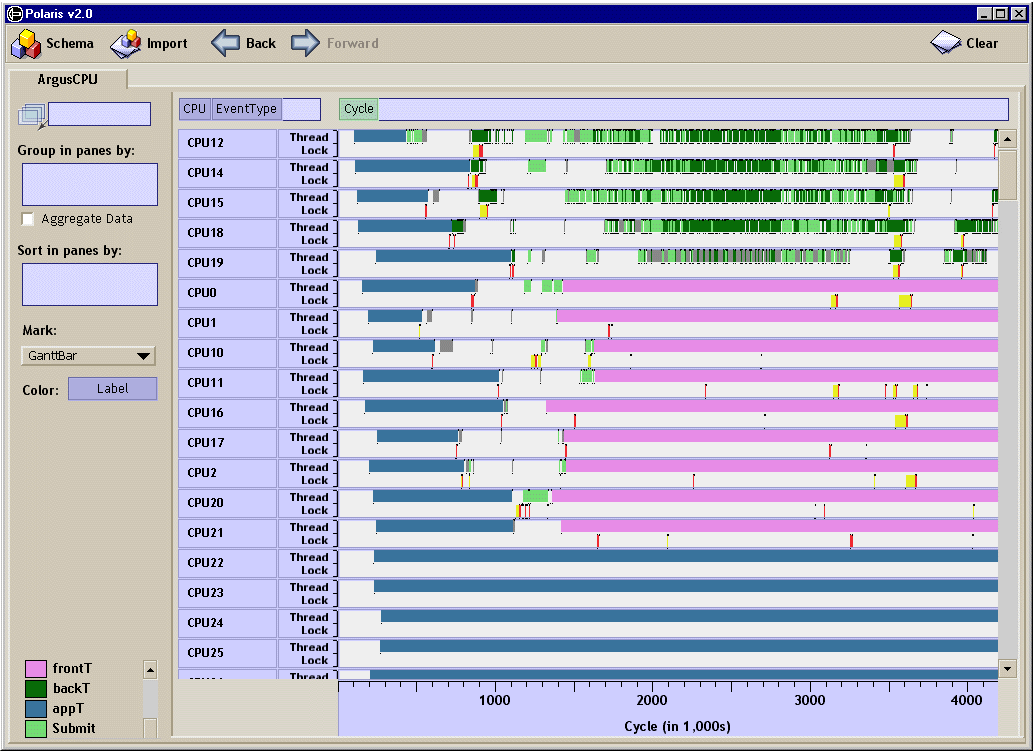
Hierarchies and Data Cubes
|
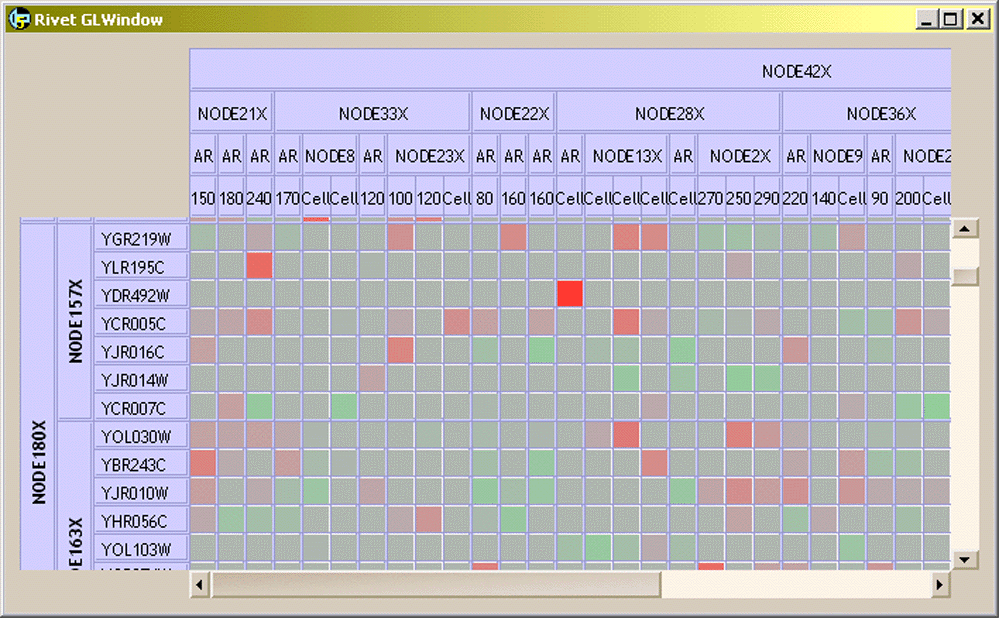
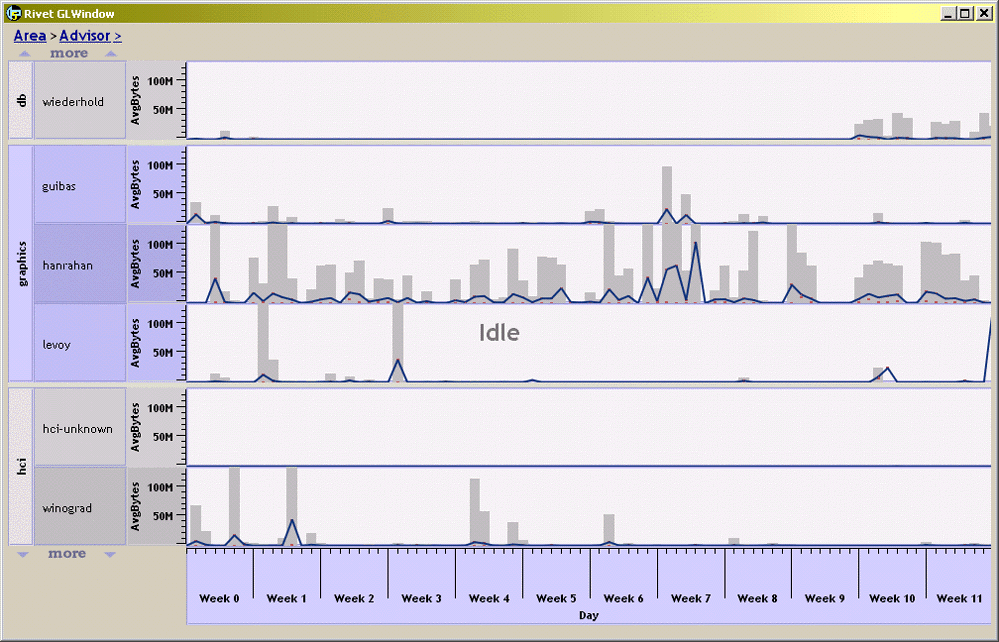
Panning and Zooming
A compelling visualization architecture is pan-and-zoom. Most analysts start with an overview of the data before gradually refining their view to be more focused and detailed. Multiscale pan-and-zoom systems are effective because they directly support this approach. However, generating abstract overviews of large data sets is difficult, and most systems take advantage of only one type of abstraction: visual abstraction. Furthermore, these existing systems limit the analyst to a single zooming path on their data and thus a single set of abstract views.
|
The Polaris formalism is an important components of these multiscale systems--it is the mechanism we use to describe the individual nodes within the zoom graphics. This work is a nice example of how the Polaris formalism can be effectively used separately from the Polaris interface as the foundation of a visualization system.
Implementation and Release
The current implementation of Polaris is built within the Rivet visualization environment. Rivet is an environment for rapidly constructing visualization from components. The majority of Polaris is written in C++ and OpenGL with some pieces written in Tcl. Data can either be directly loaded into Rivet using built in parsers (regular expressions, delimited files) or stored externally in a database or datacube and accessed through OLE DB. Rivet (and thus Polaris) runs on Windows, Linux, and Solaris.We are currently working on a new version of Polaris and Rivet that we intend to release to the public. This will likely be a native Windows application and will be available (hopefully) sometime this fall.
People
Publications
-
Multiscale Visualization Using Data Cubes
Chris Stolte, Diane Tang and Pat Hanrahan
BEST PAPER AWARD
Proceedings of the Eighth IEEE Symposium on Information Visualization, October 2002.
(paper) (slides)
Query, Analysis,
and Visualization of Hierarchically Structured Data using Polaris
Chris
Stolte, Diane Tang and Pat
Hanrahan
Proceedings of the Eighth ACM SIGKDD International
Conference on Knowledge Discovery and Data Mining, July 2002.
(paper) (slides)
Polaris: A System for Query, Analysis and Visualization of
Multi-dimensional Relational Databases (extended paper)
Chris
Stolte, Diane Tang and Pat
Hanrahan
IEEE Transactions on Visualization and
Computer Graphics, Vol. 8, No. 1, January 2002.
(paper)
Polaris: A System for
Query, Analysis and Visualization of Multi-dimensional Relational
Databases
Chris
Stolte and Pat
Hanrahan
Proceedings of the Sixth IEEE Symposium on Information
Visualization, October 2000.
(paper) (slides)
Presentations
-
"Multiscale Visualization Using Data
Cubes" given by Chris Stolte at the Eighth IEEE Symposium on
Information Visualization, October 2002.
"Polaris: Query, Analysis, and Visualization of Large Hierarchical Relational Databases" given by Chris Stolte at the DIMACS Workshop on Data Mining and Visualization, October 2002.
"Polaris: Query, Analysis, and Visualization of Large Hierarchical Relational Databases" given by Pat Hanrahan at IBM, September 2002.
"Query, Analysis, and Visualization of Hierarchically Structured Data using Polaris." given by Chris Stolte at KDD 2002.
"Polaris: A System for Query, Analysis, and Visualization of Relational Databases." guest lecture given by Chris Stolte in CS345: "Database Systems: Foundations and Frontiers" at Stanford in May 2002.
"Polaris: A System for Query, Analysis, and Visualization of Multidimensional Relational Databases." given by Chris Stolte at Infovis 1999.