Figure 1 below shows the most common approach to parallel rendering. This architecture suffers from two serial bottenecks. First, the system is driven by a serial application running on a single host CPU. Second, redistribution of primitives from the geometry processors is done by broadcasting them to every pixel processor over a serial communication system (e.g. a bus).
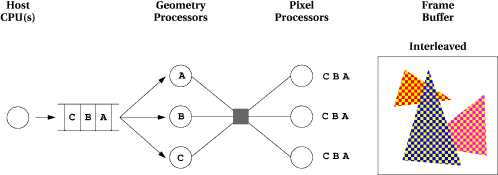
Figure 2 shows the approach taken in Argus. Argus supports multiple simultaneous user processes running on multiple host CPUs and rendering into the same scene. A point-to-point interconnect is used for communication from the geometry processors to the pixel processors. To avoid sending every primitive to every pixel processor (and negating much of the advantage of the interconnect) the frame buffer is tiled fairly coarsely across the pixel processors and primitives are only sent to pixel processors whose frame buffer regions are overlapped.
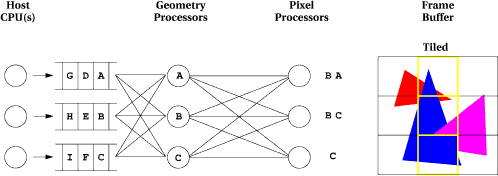
This fully parallel architecture introduces several challenging research problems. First, the multiple host CPUs have to be coordinated, and we have proposed and implemented a set of parallel API extensions to the FruGL rendering API for this purpose. Second, the commands flowing from the geometry processors to the pixel processors can get out of order due to the parallel nature of the interconnect, and Argus implements a reordering technique at the pixel processors to support strict ordering semantics and the many rendering techniques which depend on it. Finally, the coarsely tiled frame buffer can cause significant load imbalance among the pixel processors, and we have implemented and are evaluating several load-balancing techniques.
The Argus system has been demonstrated on an SGI Challenge, an SGI Origin, and an Intel SMP. Further details can be found here: