Understanding the Efficiency of GPU Algorithms
for Matrix-Matrix Multiplication
Stanford University
Stanford University
Stanford University
Presented at Graphics Hardware 2004.
Abstract:
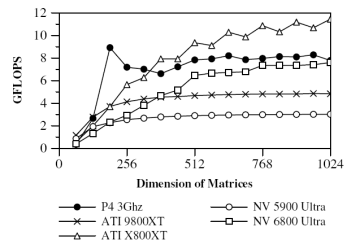
Utilizing graphics hardware for general purpose numerical computations has become a topic of considerable interest. The implementation of streaming algorithms, typified by highly parallel computations with little reuse of input data, has been widely explored on GPUs. We relax the streaming model's constraint on input reuse and perform an in-depth analysis of dense matrix-matrix multiplication, which reuses each element of input matrices O(n) times. Its regular data access pattern, and highly parallel computational requirements suggest matrix-matrix multiplication as an obvious candidate for efficient evaluation on GPUs, but surprisingly we find that even near-optimal GPU implementations are pronouncedly less efficient than current cache-aware CPU approaches. We find that the key cause of this inefficiency is that the GPU can fetch less data and yet execute more arithmetic operations per clock than the CPU when both are operating out of their closest caches. The lack of high bandwidth access to cached data will impair the performance of GPU implementations of any computation featuring significant input reuse.
Paper:
Posted 6/29/2004